This is my story of failing to make a break into AI research as an independent researcher. It’s also my take on 2019 post by Andreas Madsen: “Becoming an Independent Researcher and getting published in ICLR with spotlight.” Andreas wrote about his struggles, hard work and loneliness before finally getting some recognition but ultimately falling short of what he hoped to achieve. I’m here to tell that in 2024 the situation is much worse and that trying to get published without an academic affiliation is pretty much a waste of time.
Tips for new researchers that I’ve seen repeatedly online are to either publish with big name co-authors or to do dedicated marketing efforts. I will argue that if you are going on a marketing campaign for your academic papers, you might have as well skipped the paper writing part and just directly written a blog post, built a product or open-source project, made an educational YouTube video or otherwise engaged with the wider AI community. Academics will still want to publish papers to advance in their careers, but that’s basically the only thing papers are still good for.
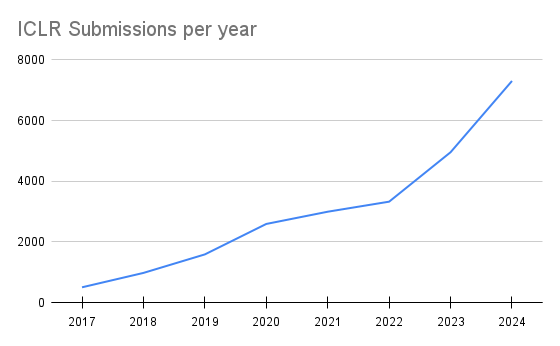
Number of papers submitted to ICLR, one of the top machine learning conferences, has more than doubled since 2022. Other big conferences are not quite as bad, but they still growing rapidly each year.
The sheer amount of new papers means that there is a constant supply of “amazing” papers and “pretty good” ones will never be discovered organically. It used to be possible to keep up with all the new developments in your own field. It’s getting harder to read even the abstracts of everything published. But if you think you can write one of those “amazing” papers, I wish you good luck. And if you succeed you only need to repeat the feat 3 to 5 times more and you might have a career in the field.
I just want to point out that something is terribly off with the field if you have to tell a researcher “don’t look at all the research coming out, it’s demotivating”. I know the feeling exactly, though.
u/officerblues
My machine learning story
In this section I’m going to recount how I ended up doing research and writing papers without academic training or academic affiliation. I think I had a pretty unique experience since the time investment needed to reach the frontier of knowledge in any particular subject is pretty massive. But it’s pretty long and personal story so I understand if at some point you want to skip to conclusions.
Hop on the ML hype train
I was late to the machine learning party. Years ago I got computer science bachelor’s decree with focus on algorithms and decision trees, etc. I used to think ML is pretty dumb all the way to the launch of ChatGPT. Suddenly it seemed like real general AI is just around the corner. But the hype was real and I started building applications with language models and tried out RAG.
To do sentence embeddings for RAG, I wrote [bert.cpp](https://github.com/skeskinen/bert.cpp). It’s a C++ library to use BERT family models written with ggml framework. It’s my most popular open source project with 450 stars and it was integrated into llama.cpp and LocalAI.io.
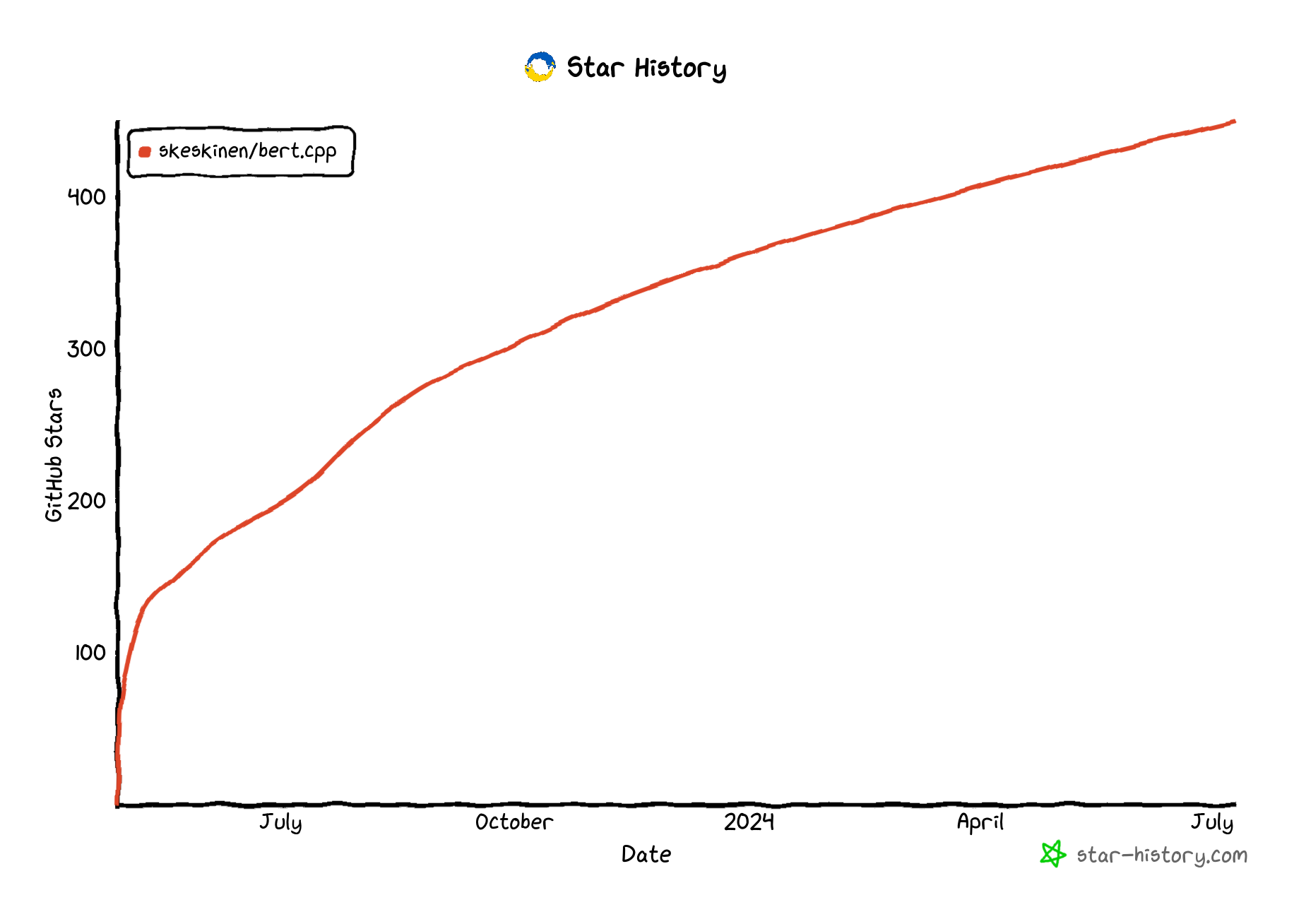
My modest open-source success in GitHub stars.
This was a very good result for me. I basically just wrote the code once, did no marketing and provided no support. People who found it useful took my work and did what they wanted with it. I didn’t really gain anything from it, but it’s still nice to see your work appreciated and a small community interacting with it. Given the introduction, you should expect that my experience with publishing novel ML research was rather different.
Six months of tinkering
Eventually I grew frustrated with the unreliability of LLMs. I found it difficult to generate structured outputs (which you need for building applications) that retain novelty (which is typically why you’d want to use LLM in the first place).
From the TinyStories paper. It shows how extremely small transformer models have learned basic storytelling. This was really inspiring work for me. If you can easily teach a model the language skills of 5-year old, then surely you can build on that and teach more complex things next?
I then shifted my focus to training my own models and went through a phase where I made every beginner mistake possible. My biggest influences at the time were the TinyStories paper and dataset which was really great to play with and Perceiver IO which eventually taught me that training models with fancy SOTA architectures is difficult.
In retrospect, this probably was the time I should have applied to do my master’s if I was ever going to be serious about doing research.
I had enough savings from my previous software engineer job that I could afford an extended sabbatical without significant financial risk. I was fueled purely by curiosity and learning. Somehow enrolling in university didn’t even cross my mind at the time. Maybe it’s because I didn’t particularly enjoy my previous time there.
After a lot of small experiments and just playing around, eventually I found my passion ML subfield of continual learning. This gets a little technical but during my tinkering I accidentally reproduced a famous result in continual learning which says that warm-starting a neural network hurts generalization.
Continual learning
Continual learning is a field of machine learning focused on developing models that can keep learning forever, adapting to new data and tasks over time. Continual learning can be roughly defined by the things we’d like to do, but that current artificial neural networks struggle with:
-
Stability: When training data or training objective changes, neural networks quickly forget what they were previously trained on, a phenomenon known as catastrophic forgetting.
-
Plasticity: Over time, models lose their ability to adapt to new training objectives, becoming less flexible and training slower. DeepMind researcher Clare Lyle has given an in depth talk about plasticity available on YouTube.
-
Warm-starting: Models previously trained on other tasks generalize worse to the test data of the new tasks, compared with models that were trained from scratch on the new task.
Continual learning aims to address and mitigate these issues, creating neural networks that can retain knowledge, adapt to new information, and apply previous learnings to new tasks effectively. Each new paper typically tries to improve slightly on one or multiple of these desired features.
If haven’t heard of continual learning before, I hope your reaction to this is “Wait, current ML can’t do any of that?” If we anthropomorphize a little, neural networks are like extreme savants that learn one thing to perfection and afterwards can’t learn anything new anymore.
These details about neural networks don’t usually come up in most ML courses, because they are not relevant to the way we train models. The way we are told to do things always starts with a fixed dataset that we split into train, test and validation sets. ML models do not need any of the continual learning features for good results at test time. Moreover, if you have a large enough set of training data (e.g. the whole internet) and general objective (e.g. predicting the next token), then the model will learn pretty general things and it will be able to do multiple downstream tasks well enough. You can even tweak the weights just a little bit after training to get slightly different outputs.
Learning about continual learning was pretty eye-opening for me. It’s such a gaping hole in the capabilities of current ML systems. The way these models are trained goes against the very core constructivist of theory of learning: that new knowledge is built on previously learned things!

Great book on learning. Shame that current AI can’t be taught anything like children can.
I was hooked. I found it fascinating how from cognitive perspective the way the AI models are trained is so clearly “wrong”. And that this isn’t perceived to be a problem except in a pretty niche research community. I also had wider ambitions of teaching concepts to AI in a controlled manner, which is clearly impossible if the models struggle to learn anything new after the first thing they learned.
It just happens that continual learning is one of the few subfields of machine learning where one can still make progress with relatively small amounts of compute resources. I think this is because a lot of the techniques don’t work very well so there is no point in scaling up the experiments. For example, this ICLR paper from 2023 only tests their technique on MNIST and CIFAR datasets, which are minuscule compared to basically anything acceptable in other subfields of ML.
Striking gold and the first paper
I got to work and spent the next three months re-implementing papers from the continual learning literature. Occasionally I ventured into continual reinforcement learning which is another very interesting subfield within a subfield. But mostly I was having better time running experiments with the classics like Memory Aware Synapses or Elastic Weight Consolidation and trying to tune them for better performance.
Exploration phase is very important in the process of creating new knowledge, but it’s also frustrating and boring at times. There is no blueprint for finding something novel so you just have to hone your intuition and try things until something works.
Eventually I got lucky and found a pretty significant novel result. Namely that choosing the correct SGD optimizer can have a massive influence on how much catastrophic forgetting happens. This was one of those best kind of discoveries were afterwards you just go “how did nobody see this before, it’s so simple”.
Table 2 of my first paper. Choosing the right optimizer improved final accuracy by a lot.
After that I just needed a few weeks to run more experiments to confirm the finding and optimize hyperparameters for even better results. I would have probably sat on the finding for a good while if it wasn’t for another strike of good fortune: I saw that the deadline for ICLR 2024 TinyPapers submissions was in just 5 days.
TinyPapers is an initiative that aims to give first time and otherwise unprivileged authors an easier way to publish their work. The papers are also limited to just 2 pages. I think 2 pages is pretty good length for a paper that has basically one good idea so I hope something like this will become more popular in the future. However, submissions to TinyPapers and similar programs are not necessarily seen as “serious” efforts, so I don’t think academics who have to prioritize their careers will want to do it.
I had not touched LaTeX in over 10 years but I pretty much had the experiment results ready so I decided to give it a shot. And somehow everything went pretty smoothly. The paper was ready on the day of the deadline and only needed minor revisions afterwards. All the reviewers liked it and it was accepted with the highest possible mark for the track (notable, invited to present). The paper is up on arXiv here.
I can’t really imagine things going much better for me, given my starting point. I was a complete outsider with no connections, no training, no co-authors and I got published at all. So why would I so strongly recommend against trying to do the same thing?
Is anybody there?
Why do I feel like getting published was not worth it for me in the end?
After careful consideration, we regret to inform you that we are unable
to proceed with your application for this year’s conference. Please note
that we had an overwhelming response to our call for financial
assistance — in particular, this year we received a three-fold increase
in number of applications while facing a 50% reduction in budget; and we
admit that it is an imperfect process – we must make hard choices with
limited information. Please take this decision in that spirit.We appreciate your commitment and enthusiasm for ICLR and would like to thank you for taking the time to apply.
- Notification about ICLR financial assistance.
One reason has to do with the organization of the TinyPapers track itself. Right now if you search online, you can’t even find a list of accepted papers anywhere. No blog post or anything. They might as well not exist. Virtual presentations were cancelled 2 weeks before the conference (altho they warned that might happen beforehand).
Despite the invitation to present, I did not attend the conference. The conference tickets are $1000 for people without academic affiliation and my financial assistance request was denied. At least TinyPapers track doesn’t have mandatory attendance unlike the main conference track. Also the in person presentation slots for TinyPapers were 5 minutes each, which feels a little insulting after travel, etc. I guess this is just how the system is.
I think that just like the authors, many of the organizers of ICLR are overworked and underappreciated. I trust they are trying to do their best and they were always pleasant when contacted through e-mails. Still, many aspects of the process feel pretty dehumanizing.
The main reason it feels like writing the paper wasn’t worth it is that the whole exercise is like shouting to the void. ArXiv unfortunately doesn’t show any analytics on uploaded papers, but on ResearchGate I can see that the paper has been opened less than 10 times. On HuggingFace they have pretty much 0 engagement. And of course 0 citations and I’ve been reached out to about them 0 times. I guess the reviewers read it so that’s something (unless they just fed the paper to a chatbot). I’ve also shown it to couple researchers in private conversations and received reactions on the level of “cool”.
Seeing a paper you worked on for months get read about ten times is pretty sad. For reference, the 2 weeks old landing page here, https://smartmediacutter.com, gets more traffic than that each day just from Google, and I haven’t even done any marketing yet! Building the software and the website for the media cutter took about as much effort from me as the two papers did, but the potential upside is completely different. Now I actually have an interesting product to sell to people.
The second paper
I still had a little bit of hope and passion for research in me and I thought it would have been nice to visit a conference at least once.
I had two more semi-working ideas that I thought might be paper worthy:
-
A variant on real time recurrent learning, kind of like this, but using extremely sparse activation function to make the computation of the jacobian possible without approximations.
-
Continual learning with modified neural network architecture that replaces some matrix multiplications with more complex operation that can look for correlations in the latent space.
I went with the second idea, since it was close to the continual learning experiments I had done for my first paper. This one would be a more typical 8-9 pages long and I would try to submit it to CoLLAs 2024 conference.
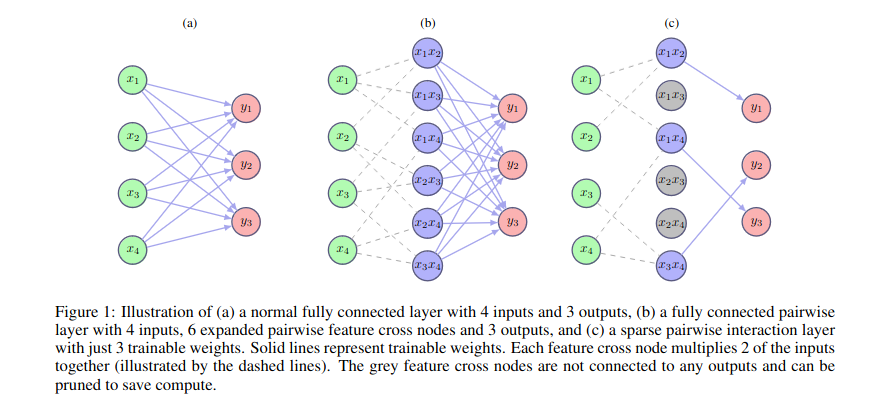
Figure from my second paper, illustrating the architecture innovation. Simple linear matrix multiplication is replaced with an operation that looks at pairs of inputs firing at the same time.
Writing of this paper was tough. Everything was more complex and the experiment results weren’t always perfect. The writing itself was harder as I was trying to explain more advanced concepts and there were more experiments and benchmarks to compare to.
In the end I wasn’t surprised when the paper was rejected by the reviewers. They weren’t against the core ideas in the paper, but they wanted me to do a lot of changes. I was already burned out and checked out so I didn’t care to implement those changes.
There is no payoff for any of this work unless you are already inside the academic system. Think of all the things you need just to have a successful paper: first you need to be expert in your field to come up with a workable novel idea, programming skills to implement the idea, time and compute resources to do experiments, communication and presentation skills to write a good paper and then you still need to market your paper through blog posts, presentations, social media, workshops, etc. to have people actually look at it. This is basically same as building a startup! At least when you write your first papers in university you’re supposed to get help from your advisor and other students.
I think the architecture I came up with has potential. There are some ideas in the “future directions” section of the paper that I wish I had time to try. The writing and the paper itself definitely needed more refinements. Here is a link to the rejected pre-print version of the second paper on arXiv.
What was it like getting your first paper published?
It felt cool for like a day, but then I had the realization that the rest of an academic career is just doing that over and over again. It feels pretty good each time, though, but not as great as the first time.
u/seesplease
At this point I finally realized that there was no future for me in research. Thousands and thousands of PhDs have gone through all of this and are competing for a relatively fixed amount of industry research positions. I realized I do not have what it takes to make it in AI research. If I absolutely had to stay in research, the very best result I could hope for is to go to university, spend 4-7 years there trying to publish over and over until hopefully getting PhD that might be worth something.
The Saturation of AI Research
Saturation — to a very full extent, especially beyond the point regarded as necessary or desirable.
Many of the problems I faced have common root. The competition in the AI research is crazy intensive. There are many more potential researchers than there is any real demand for their services. Related reading is this post titled Folks here have no idea how competitive top PhD program admissions are these days, wow…
FYI most of the PhD admits in my year had 7+ top conference papers (some with best paper awards), hundreds of citations, tons of research exp, masters at top schools like CMU or UW or industry/AI residency experience at top companies like Google or OpenAI, rec letters from famous researchers in the world, personal connections, research awards, talks for top companies or at big events/conferences, etc… These top programs are choosing the top students to admit from the entire world.
Don’t want to scare/discourage you but just being completely honest and transparent. It gets worse each year too (competition rises exponentially), and I’m usually encouraging folks who are just getting into ML research (with hopes/goals of pursuing a PhD) with no existing experience and publications to maybe think twice about it or consider other options tbh.
u/MLPhDStudent[](javascript:void 0)
There are clear societal pressures that have led to this situation. Going to university is an investment in ones future and naturally people don’t want it to go to waste. So it feels like the safest thing to do is to study the fanciest of fields, which is AI/ML. Why go study anything else if AI is going to make most forms of labor obsolete? (any time now, surely)
At the same time the amount of research positions in the universities or the industry isn’t growing nearly at the same rate. There has been some growth during the recent AI boom, but not on same scale with the new people trying to get in. Once students realize that all the career options in the field are ultra competitive, there is even more pressure to get into the top PhD programs that require crazy amounts of publications. The risk that the diploma from an average university isn’t going to give you the job you want is too high.
These are the kind of incentives that lead to doubling of new AI research papers roughly every two years.
In my case these pressures are bad enough that I don’t want to have anything to do with research anymore. Even though I like many aspects of the research process and spent quite a lot of time getting better at it, I’m still at the point where I can cut my losses and pursue something else. This is one nice thing about having gone through all this as an independent; I don’t have to quit school if I never enrolled in the first place!
The current rate of publishing also leads to just following the field becoming harder and harder. In the not so distant past, it was feasible for researchers to read all the new papers in their field. Today, the volume is so high that even scanning the abstracts can be stressful. New papers have no discoverability and most people who are trying to get in are going to be disappointed.
I was pretty naive
During my research efforts I had read the post by independent researcher posts by Andreas Madsen a few times. Looking back at it, it’s pretty clear I didn’t really grasp what I was getting into. Andreas already had master’s degree, previous research experience, contacts in the field, list of places where he’d like to apply after improving his publishing record, etc.
I had none of the these things and never will. I only had one years worth of enthusiasm for research and blissful ignorance. I was never going to have the credentials or the commitment required to make it to industry research or research engineer positions. It just took me a while to figure that out.
I’m spending 4 years of my life in an environment I don’t really like, just to become overqualified.
Andreas Madsen
It’s also worth noting that Andreas, despite all his experience and viral success, didn’t land any of the job opportunities he hoped for and started a PhD. I’ve read comments online saying he came across as entitled and that he should be grateful for the position that he got. I think these comments come from people who feel the same of pressure to get ahead. Apparently the appropriate reward for a year of hard work is to get to do it all over again four more times, all while contributing to propagation of a deeply flawed system.
When I look at AI research in 2024, I see a lot of human suffering and broken dreams. Thousands of highly talented and motivated individuals are engaged in a system that requires unhealthy amounts of effort and competing against your fellow students. And all of this is happening in the name of science.
I used to think that academia had only pure intents. Listening to my friends outside of research and academia, I think many share that belief. However, once you become a part of academia, that illusion fades, and we see that academia is not an excellent implementation of science
Andreas Madsen
Closing Thoughts
Research should not be an end in itself. We do it because we love it, but the end goal should be creating value to people. Personally, I now see that it’s easier to create value with a more direct approach—building something that people will actually use. With all the steps and skills involved in doing research, I’m sure a lot aspiring researchers could become more product oriented with the right motivation and a little push.
Personally, I have always been passionate about research… However, as I’m getting older, this passion has quickly been drained by this self-referential, conservative world.
I think the research world is not anymore for disruptive, creative, progressive thinkers.A professor in ML
I used to believe that the purpose of research was to inspire follow-up research and product development. I now see that most research exists only to feed the beast of academia—grants, citations, impact factors—and to advance the authors’ academic careers. The idea of making a significant scientific discovery and having other scientists build on that is still appealing to me. I just don’t think it will ever happen to me, or most researcher for that matter. This realization drove me to shift my focus from research to developing practical tools like Smart Media Cutter, which I hope will make a tangible difference in the lives of streamers and podcasters.
For those passionate about AI, there are numerous alternative paths that can be both fulfilling and impactful. Whether it’s through industry roles, open-source contributions, side hustles, or a different academic focus, there are ways to stay engaged with AI and make meaningful contributions without the frustrations that come with trying to publish ML research. My next post on this blog is a summary of the best opportunities I see in the space.